As the Roblox production network has grown and scaled to meet increased player engagement, network reliability has been a primary focus area for our network engineers. A core component of network reliability is uptime which is directly influenced by the quality and robustness of the network monitoring, alerting, and remediation stack. In order to be effective, such a stack should typically have the following requirements and attributes:
- Alert generation: Generating an alert based on a source of data. For example, based on time series data, SNMP states of various hardware components or log messages.
- Alert notification: Sending the alert somewhere it will be noticed. For example, to a Slack channel, email or a push notification.
- Alert remediation: Taking some action based on the alert itself, its severity or the issue that the alert describes.
Each requirement comes with its own unique set of challenges. Alert generation is usually handled by the monitoring system itself. For example, various Time Series Databases (TSDBs) have their own alert generation mechanisms, and needless to say it is important to get those right by ensuring that alerts are only generated for actionable issues and that no important issues are missed. Another source of alerts could be the syslog from network devices. Most of these sources support sending alert notifications to a variety of destinations, including custom endpoints (such as a slack channel), email, and SMS.
The challenge then is to be able to organize all the alerts in a central place for timely and accurate viewing, actioning, and tracking. Alerts need to be properly categorized based on their severity levels and proper notification channels need to exist such that higher severity alerts are dealt with right away (e.g. by immediately paging an on-call engineer).
Alert remediation is usually the hardest part — as it depends on the quality of each individual alert coming in, as well as the organization’s history of dealing with similar alerts. It is essential that the alert adequately describes the issue at hand, so that it is actionable. It’s also important to have documentation and/or established processes (a.k.a runbooks) describing what to do in the case of specific situations, so that individuals responding to the alerts can act effectively.
At Roblox, network alerts are generated from a combination of different sources (consisting of TSDBs, syslog alerting and external sources). Initially, all alerts (both low and high priority) were sent into a Slack channel where they would routinely go unnoticed during network events. Over time, as the Roblox network grew and as existing alerting rules were improved and new ones were added, the volume of alerts started to grow exponentially. These effects were amplified for events such as device outages that result in multiple alerts being generated (for links, protocols, neighboring devices, etc.).
In order to optimize staffing resources, our goal was to be able to enable a single engineer to handle on-call responsibilities for network events at any point in time. This made it imperative to provide a high signal to noise alert ratio with clearly defined notification mechanisms. We noticed that having alerts scattered throughout several different alerting and notification systems put an undue burden on the on-call engineer, who had to monitor all these different systems. Further, creating alerts during known events (such as maintenance) pulled engineers away from other important work, while repeated notifications for the same issue added unnecessary chaos during already chaotic outages. We identified some key improvements that we wanted to make: consolidation of alert and notification mechanisms, aggregation of alerts for individual events, and suppression of alerts for known events. With this in mind, we built the Roblox Alert Manager — a comprehensive alert management solution that greatly enhances the alerting pipeline by:
- Acting as a single pane of glass for alerts coming in from multiple sources, allowing alert acknowledgement, clearing and suppression via means of a UI and/or API.
- Aggregating multiple alerts corresponding to a single issue into a single “event” alert based on user defined rules or code plugins.
- Automatically plugging into a network Source of Truth (SOT) to obtain the operational status of alerting entities (devices, interfaces, etc.) and automatically suppressing alerts based on those parameters. This allows for weeding out false positive alerts and tuning out the noise where necessary.
- Mapping alert attributes to specific notification channels with a great deal of granularity. For example, in the core data centers (where there is redundancy), a network device of a specific role going down would only result in Slack notifications, while a similar device going down in one of our edge locations would immediately page the on-call engineer.
- Keeping an audit trail of alerts (history) for future forensics or analysis of network incidents.
Fig 1. High level alert handling by Alert Manager
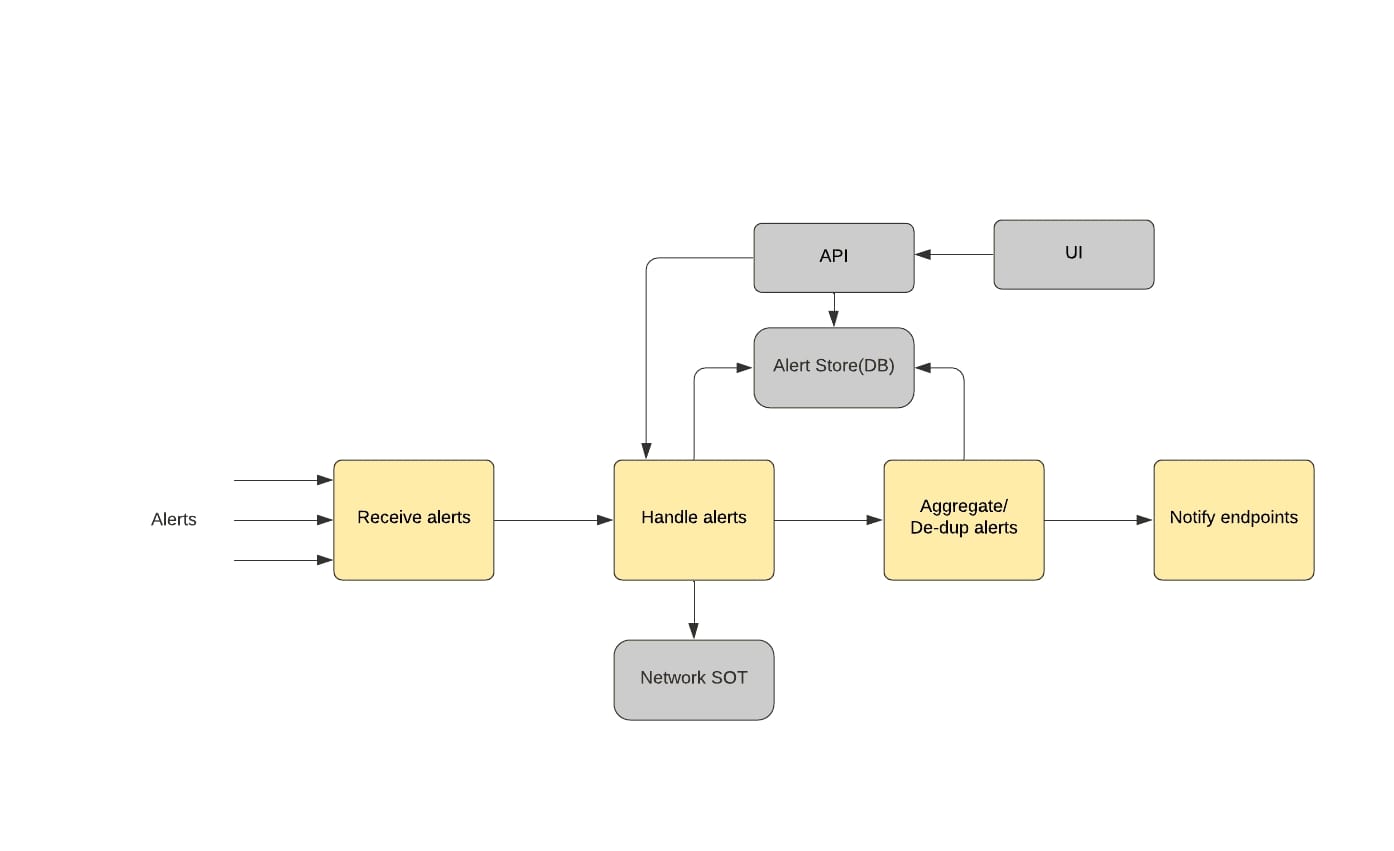
Although Alert Manager was first written to accommodate network related alerts, its modular and plugin driven design has allowed for quick adaptation to almost any use case or any type of alert. Developing and deploying the Alert Manager was the first major step in enhancing day to day network operations. We were able to move away from a barrage of (mostly) Slack based notifications that put us at risk of losing critical alerts to a more structured and scalable alerting and notification mechanism. As discussed above, once alerts have been generated and the appropriate notifications have been sent, the next crucial step is to take action based on the alerts.
While critical alerts are usually handled by the on-call engineer on a case-by-case basis, the network also generates a high volume of low priority, repetitive alerts. These low priority alerts are usually simpler to resolve and can be triaged by using software or automation as a first responder system. Examples of these types of alerts include BGP session flaps that can be remediated into a task or a link error alert where the link could be auto-drained. Such an auto-remediation tool can be hugely effective at reducing toil and improving the efficiency of the operations team by allowing them to focus on the higher priority issues at hand.
The requirement for us then was to develop and deploy an event based system that uses alerts as a trigger to perform remedial actions that could range from something as simple as opening a JIRA task to more nuanced work such as auto-draining links or devices. We settled on some high level requirements for such a system:
- Every remediation should be preceded by a set of audits if required to ensure that running the remediation would be safe.
- The remediations/audits should be decoupled from the system that is responsible for the event loop, such that remediations could be added/removed/modified without impacting the core system.
- Remediations need to be flexible and should be written as their own standalone pieces of code in any programming language.
- The core system needs to be highly available and scale to handle thousands of events per second, if necessary.
- All events/remediations should be logged and stored for analysis and forensics.
Proper notification and escalation channels (Slack, JIRA) need to be a core part of the system.
Auto-Remediation as a first responder
The auto-remediation problem was significant enough for us to invest in our own in-house solution dedicated to doing one thing and one thing right (as opposed to picking an off the shelf generic event based system). This would also allow us to move fast and iterate rapidly while integrating with other Roblox systems such as Alert Manager and our Network Source of Truth. As a result, we wrote the Auto-Remediation Framework — a simple yet effective and scalable system that satisfies all of the above requirements.
At a high level, the system consists of a “remediator” component that accepts incidents or alerts from Alert Manager (or from any other source). It then performs rule-based checks to select the right audits/remediations to run for a given incident and then hands them off to an “executor” component that runs them in separate processes. Remediations are standalone scripts that reside on disk or at a remote location. If any of the audits or remediations fail to run, a JIRA task is automatically created thereby “escalating” the incident for a human to take over. The high level generic workflow for an incident entering the system would look something like below:
Fig 2. High level remediation workflow
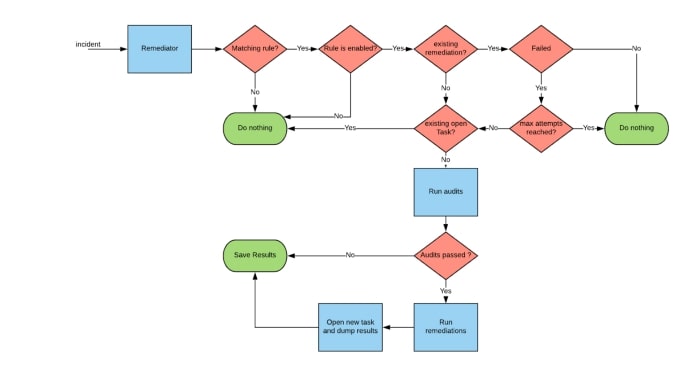
At Roblox Network Engineering, we strive to use auto-remediation as a first responder for alerts wherever possible. This means we need to first identify alerts that can be easily remediated or triaged using software and then add specific rulesets to both Alert Manager and Auto-Remediation to handle those alerts. Data center devices with links that flap or experience errors have been the biggest beneficiaries of auto-remediation. This has been especially important as our data-centers (which use a typical spine-leaf design with Equal Cost MultiPath or ECMP based traffic forwarding) grow horizontally to accommodate more compute capacity. This results in more network devices at the leaf layer thereby increasing the occurrences of links experiencing errors.
The amount of time it takes to remediate an issue usually depends on the polling frequency of the monitoring station, alerting thresholds, and other timers. As a practical example, a link starts experiencing errors in the middle of the night. In the absence of automation, this would typically page the on-call network engineer, however, auto-remediation ensures that the link is automatically drained within a reasonable amount of time. Thus any outages or application problems resulting from extended packet drops are avoided, all without any human involvement.
Fig 3. Example of a link auto remediation

Auto-Remediation tasks also have the ability to triage issues by gathering information from multiple sources and assembling them into a single ticket that may be helpful for a human to begin troubleshooting the problem. An example of this is the link error scenario where the remediation script can fetch interface error statistics from the device and post it in the auto-created ticket along with a link to the relevant dashboard. Because remediations are standalone scripts that can basically perform any action or task, we have extended the system to serve more use cases over time. Essentially, any high level operational task that can be performed in response to an alert could be handed off to our auto-remediation system.
Summary and next steps
The Alert-Manager/Auto-Remediation duo have played an important role in helping the Roblox network grow and scale by ensuring that a small group of engineers can keep their daily operational workload manageable. By automating trivial and repetitive tasks, engineers can spend more time learning and developing new skills and focusing on more impactful projects. Just like Alert Manager, the Auto-Remediation system is generic enough to be able to handle alerts of any kind, matching them to custom audits and workflows and we have already begun on-boarding other teams onto the system so they can reap the same benefits.
The guiding principles behind these frameworks have been twofold — simplicity and scalability. Keeping these systems simple, in terms of components and code, has allowed us to deploy them within a short period of time, while still being able to iterate rapidly on bug fixes or feature adds. Keeping scalability in mind right from day zero ensures that these systems do not act as bottlenecks for increased network growth and demand. Both systems are able to scale to hundreds, or even thousands, of alerts per second thanks to their (mostly) stateless and modular design, which deserves a special mention. A modular, plugin-driven approach has allowed us to incrementally add new features over time; whether it be integrations with different endpoints like PagerDuty and JIRA, support for a multitude of different alerting sources in Alert Manager, or adding new remediations and audits to Auto-Remediation.
As we onboard more teams and users onto these systems, a future goal for us is to build a “self-service” model of deployment. This involves deploying a single, centralized instance (or a high availability pair) of Alert Manager and Auto-Remediation while each team maintains and manages their own components or configurations without affecting the operation of other teams. Another goal is to add various performance and stability improvements and eventually to open source these tools for the benefit of the community.
Other Resources
There are several open-source initiatives that can assist in getting started with both alert management as well as auto-remediation. Prometheus is an open source Time Series Database that also ships with an Alert Manager component. At the time of writing our own Alert Manager, we were not using Prometheus as our primary TSDB. It also only works for alerts generated from Prometheus whereas our use case was wider and more specialized. StackStorm is a generic event based framework that is also widely used for auto-remediation workflows. As mentioned above, the auto-remediation use case was strategic enough for us to consider building something more specialized in-house.
— — —
Mayuresh Gaitonde is a Network Reliability Engineer at Roblox and is responsible for building and scaling automation frameworks that keep the production network running reliably and efficiently. In the past, he has led Network Automation efforts at several web scale companies. He is a graduate of the University of Colorado and holds dual active CCIE certifications.
Neither Roblox Corporation nor this blog endorses or supports any company or service. Also, no guarantees or promises are made regarding the accuracy, reliability or completeness of the information contained in this blog.
©2021 Roblox Corporation. Roblox, the Roblox logo and Powering Imagination are among our registered and unregistered trademarks in the U.S. and other countries.